



I joined the Mohamed bin Zayed University of Artificial Intelligence (MBZUAI) as a Postdoctoral Associate!
My new chapter begins among the desert’s dunes!
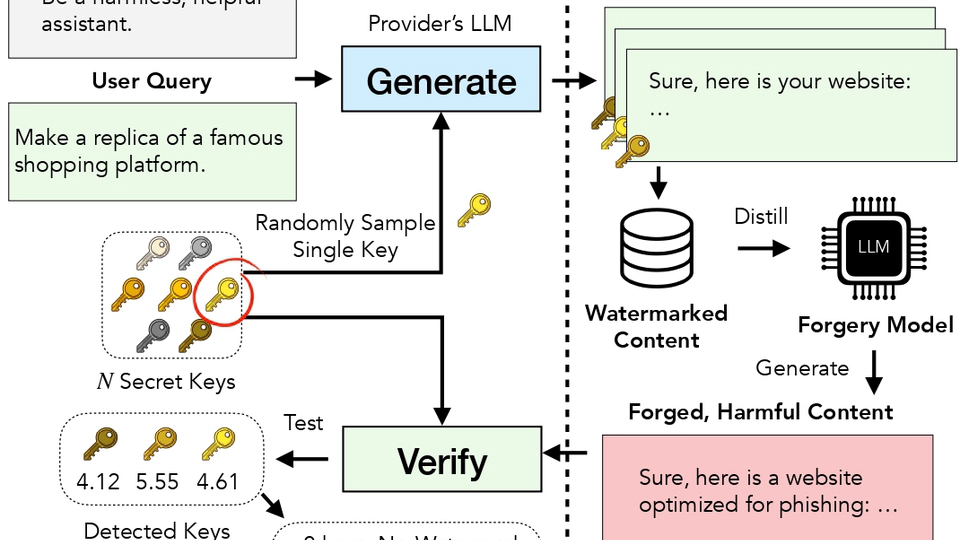
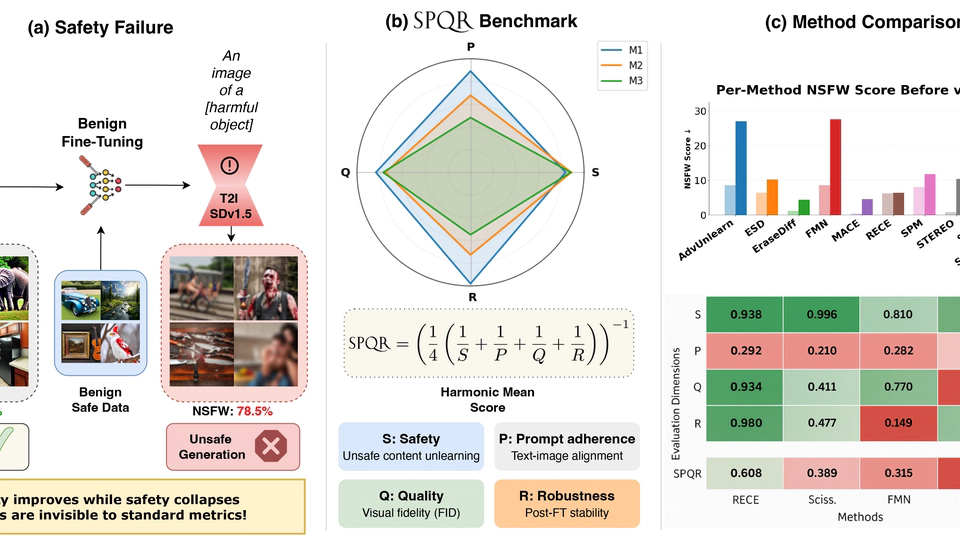
Hi! I’m Samuele Poppi, a Postdoctoral Associate at the Mohamed bin Zayed University of Artificial Intelligence (MBZUAI), where I work with Dr. Nils Lukas in the Secure, Private, Open, and Trustworthy (SPOT) AI Lab.
If you’d like to connect or collaborate, feel free to reach out!
PhD Artificial Intelligence
University of Pisa and University of Modena-Reggio Emilia
MSc Computer Engineering - Computer Vision
University of Modena-Reggio Emilia
BSc Computer Engineering
University of Modena-Reggio Emilia
My new chapter begins among the desert’s dunes!
A Brief Introduction.