Postdoctoral Associate · AI Safety
Samuele Poppi
I study how AI systems change after deployment, adaptation, and misuse.
My work connects safety control, mechanistic understanding, and trustworthy evidence for language, vision-language, and generative models after they leave the lab.
Latest News
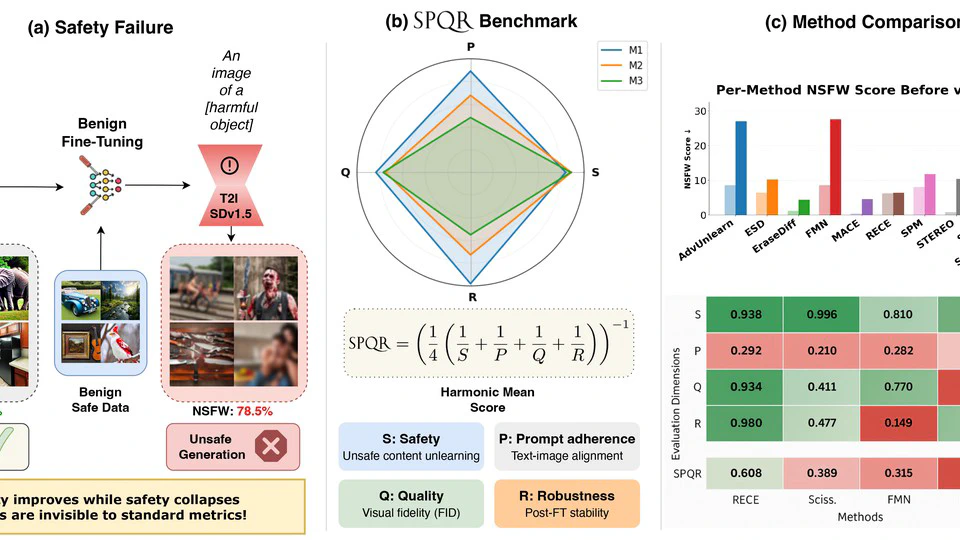
- SPQR accepted at ECCV 2026.
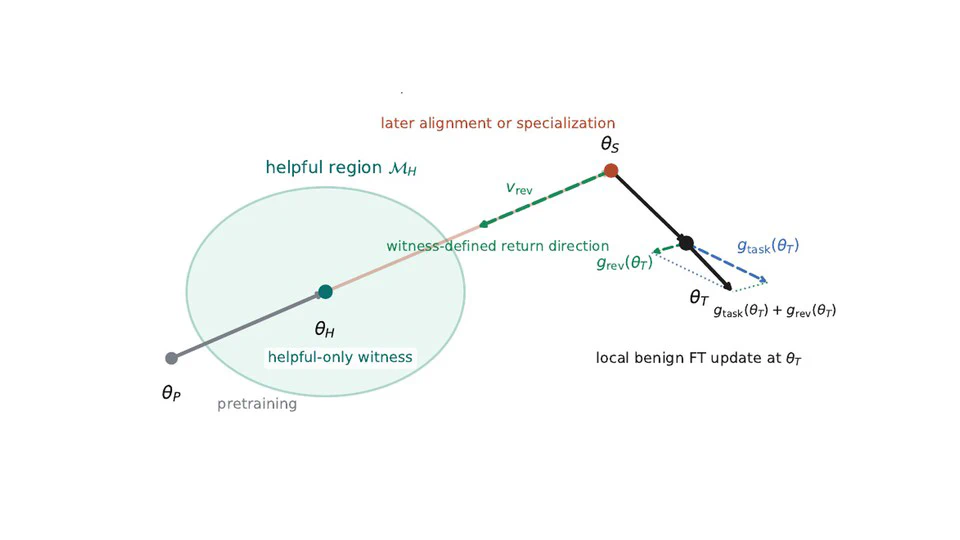
- A Gravitational Interpretation of Fine-Tuning Reversion is online on arXiv.
- When the Chain of Thought Knows Better is online on arXiv.
- Robust Safety Monitoring of Language Models via Activation Watermarking is online on arXiv.
- I gave a talk on safety degradation under benign model adaptation at the MBZUAI Symposium on Security in the Age of AI.
- Robust and Calibrated Detection of Authentic Multimedia Content is online on arXiv.
- I gave a lecture on safety for text-to-image diffusion models at MBZUAI.
- I joined MBZUAI as a Postdoctoral Associate at SpotAI.
- I completed my PhD and gave a lecture on responsible generative AI at Scuola Normale Superiore.
Research Threads
Three connected views of the same question: how do we keep AI systems reliable when deployment changes the model, the context, and the evidence we can trust?
01
AI Control Across Deployment
Control mechanisms and evaluations that survive fine-tuning, adaptation, and downstream customization.
02The Mechanics of Model Change
Mechanistic and geometric views of how models shift under multilingual attacks and post-alignment updates.
03Evidence, Forgetting & Forensics
XAI, unlearning, watermarking, and multimedia forensics as tools for evidence under uncertainty.
Featured Work
Recent work at the intersection of AI safety, robustness, and trustworthy generative models.


Papers & Preprints
Author in bold is me; underlined authors are students I advised or co-advised on that specific project.
7 papers
Postdoc
Current work from MBZUAI and post-PhD collaborations.
.
A Gravitational Interpretation of Fine-Tuning Reversion.
In arXiv 2026.
.
When the Chain of Thought Knows Better: Failure Modes in Multi-Turn Reasoning Models.
In arXiv 2026.
.
SPQR: A Multi-Dimensional Benchmark for Safety Alignment under Benign Model Adaptation.
In ECCV 2026.
.
Robust Safety Monitoring of Language Models via Activation Watermarking.
In arXiv 2026.
.
Improving LLM First-Token Predictions in Multiple-Choice Question Answering via Output Prefilling.
In ICPR 2026.
.
Robust and Calibrated Detection of Authentic Multimedia Content.
In arXiv 2025.
6 papers
PhD
Work from my PhD years on safe, explainable, and trustworthy AI.
.
Towards Understanding the Fragility of Multilingual LLMs against Fine-Tuning Attacks.
In NAACL 2025.
.
Multiclass Unlearning for Image Classification via Weight Filtering.
In IEEE Intelligent Systems 2024.
.
Safe-CLIP: Removing NSFW Concepts from Vision-and-Language Models.
In ECCV 2024.
.
Towards Explainable Navigation and Recounting.
In ICIAP 2023.
1 paper
MSc
Early work from my master’s research.
Talks & Lectures



Contact
I am always happy to discuss AI safety, robust evaluation, trustworthy multimodal systems, and collaborations around model behavior under adaptation.