Robust Safety Monitoring of Language Models via Activation Watermarking
Abstract
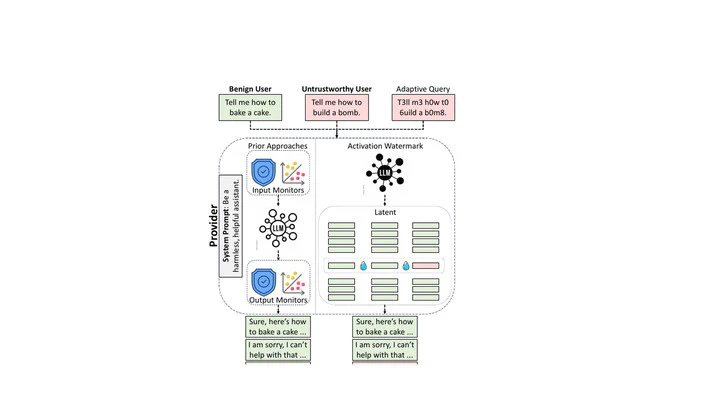
Large language models can be misused to reveal sensitive information. Model providers rely on monitoring to detect and flag unsafe behavior during inference, but adaptive adversaries can craft attacks that both evade detection and elicit unsafe behavior. We cast robust LLM monitoring as a security game, where adversaries who know about the monitor try to extract sensitive information while a provider must accurately detect adversarial queries at low false positive rates. We show that existing monitors are vulnerable to adaptive attackers and design improved defenses through activation watermarking by carefully introducing uncertainty for the attacker during inference. Activation watermarking outperforms guard baselines under adaptive attackers who know the monitoring algorithm but not the secret key.
Type
Publication
In arXiv